
Ακόμα μαζί με τα ελληνικά μπορούμε να εγκαταστήσουμε και άλλες γλώσσες όπως γαλλικά, γερμανικά, ρώσικα κτλ
Σαν γραφικό περιβάλλων θα χρησιμοποιήσουμε την εφαρμογή που υπάρχει στο κέντρο λογισμικού OCRFeeder
Την διαφορά για την υποστήριξη των ελληνικών την κάνει το tesseract στην έκδοση 3.
Στο Ubuntu 12.04 υπάρχει στα αποθετήρια μαζί και τα αρχεία αναγνώρισης γλώσας, οπότε εγκαθιστούμε :
OCRFeeder, tesseract, αρχεία γλώσσας (πχ tesseract-ocr-ell)
Για να έχουμε καλά αποτελέσματα πρέπει τα σαρωμένα κείμενα να είναι σε 300dpi και να έχουν καλό κοντράστ.
Αν σας βγάζει αρκετά λάθη να είστε επιεικής είναι το πρώτο βήμα OCR ελληνικών σε linux. Ακόμα στην σελίδα του project υπάρχει και ειδικό πρόγραμμα για "εκπαίδευση" του OCR για καλύτερη αναγνώριση.
http://code.google.com/p/tesseract-ocr/wiki/TrainingTesseract3
Στο πρόγραμμα OCRFeeder πάμε Εργαλεία -> Μηχανές OCR
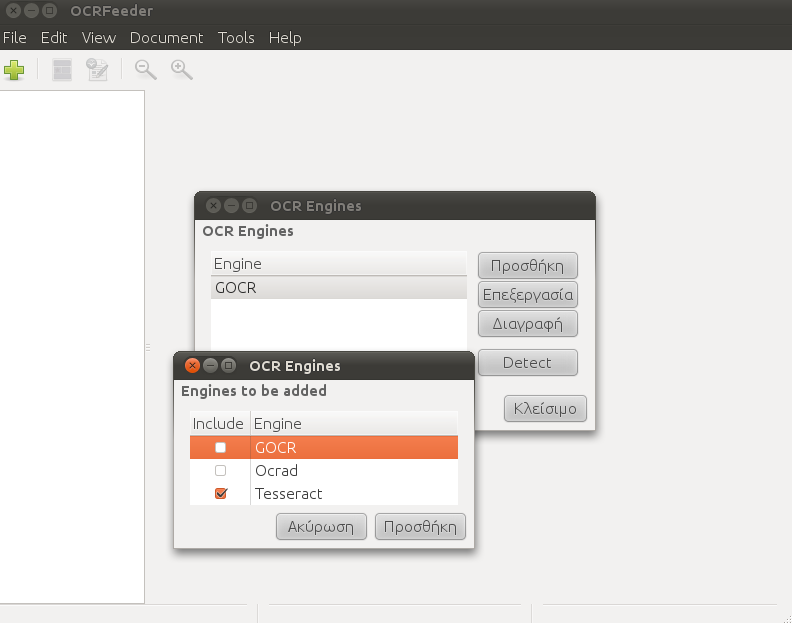
Πατάμε Tesseract, Επεξεργασία
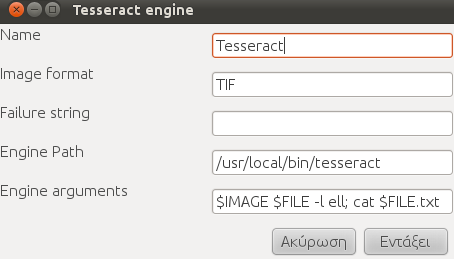
Αλλάζουμε την εντολή
- Κώδικας: Επιλογή όλων
$IMAGE $FILE > /dev/null 2> /dev/null; cat $FILE.txt; rm $FILE $FILE.txt
σε
- Κώδικας: Επιλογή όλων
$IMAGE $FILE -l ell > /dev/null 2> /dev/null; cat $FILE.txt; rm $FILE $FILE.txt
Αν θέλουμε άλλη γλώσσα βάζουμε το αντίστοιχο πρόθεμα πχ -l rus (είναι L μικρό όχι ένα)
Αν θέλουμε να αναγνωρίσει ένα κείμενο με 2 ή περισσότερες γλώσσες βάζουμε
- Κώδικας: Επιλογή όλων
$IMAGE $FILE -l ell+eng > /dev/null 2> /dev/null; cat $FILE.txt; rm $FILE $FILE.txt
Υπάρχει η πιθανότητα να αυξηθούν τα σφάλματα αναγνώρισης με αυτή την επιλογή
Και είμαστε έτοιμοι !
Για εκπαίδευση του προγράμματος σε μια νέα γλώσσα ή σε πολυτονικό δείτε εδώ
http://code.google.com/p/tesseract-ocr/ ... Tesseract3
Παλαιό κείμενο οδηγού
Spoiler: show

Η εργασία υπάγεται στην άδεια Creative Commons Αναφορά-Μη εμπορική χρήση-Παρόμοια διανομή 3.0 Ελλάδα




